728x90
목적
Sputter 데이터는 온도, 기압, 전류 등 다양한 센서 데이터가 포함된 multivariate-time series data이다.
이러한 multivariate-time series 데이터를 처리하기 위해 이미지 인코딩 방식을 채택해 Image Classification으로 정상, 비정상, 비가동 데이터를 구분해 Anomaly Detection 문제를 해결하고자 한다.
최종적으로 비정상 데이터로 분류된 이미지의 confidence score를 위험도(anomaly score)로 해석해 장비의 실시간 위험 정보를 파악하여 예지보전 모델을 개발할 수 있다
방법론
1. 데이터 전처리
1) 분석에 사용될 센서 데이터 파라미터만 필터링
- 카테고리값 제거
- lot ID, substrateID, slot, recipe, step, stepname, status 등
- step과 slot 파라미터는 중복 (똑같은 정보임에도 step, Step Number 라는 다른 파라미터가 존재)
- ~ Max 값 제거
- Target Life Max, Process Kit Life Max, Shutter Disc life Max, Preventive Maintenance Wafer Count Max 등
- ~ Max가 붙은 파라미터는 해당 공정에서 사용되는 장비의 최대 사용량(소모량)을 단순히 표시한 값이며, 실시간으로 수집되는 센서 데이터 파라미터와 다르게 처리되어야 할 것으로 판단되어 우선 필터링했습니다
2) data scaling
3) 비가동시간의 결측치 처리
4) 이미지 크기 맞춤
2. 데이터 클래스 분류
- 정상 : 알람 정보도 없으며, 비가동 시간도 포함하지 않을 경우
- 비정상 : 시점 내 알람 정보가 있을 경우
- 비가동 : 4초 이상의 비가동이 있을 경우 (3초까지는 데이터 딜레이로 인한 것일수 있기 때문, 실제로 DB상 1-2초의 데이터 딜레이는 빈번히 발생)

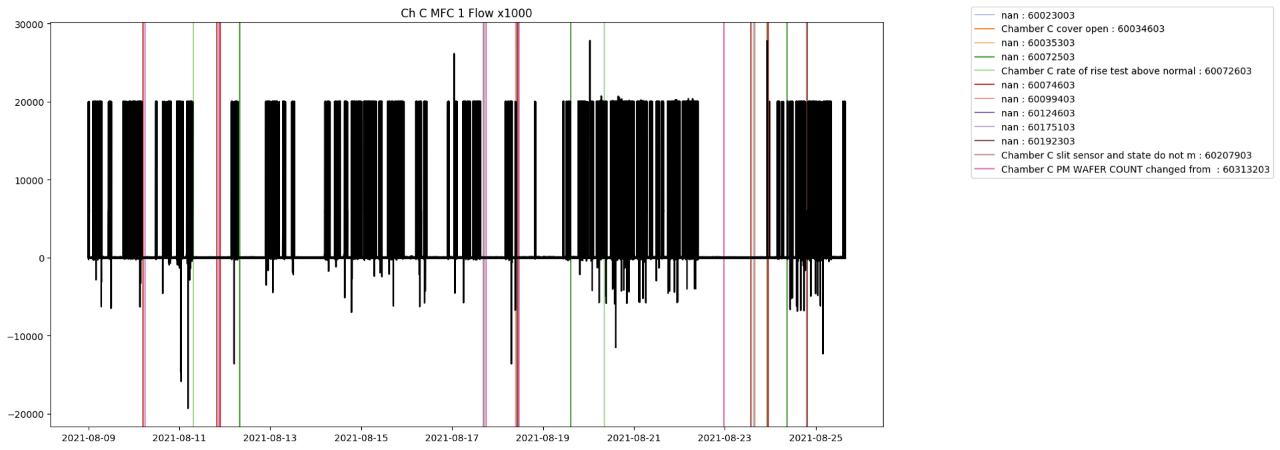
3. 이미지 인코딩
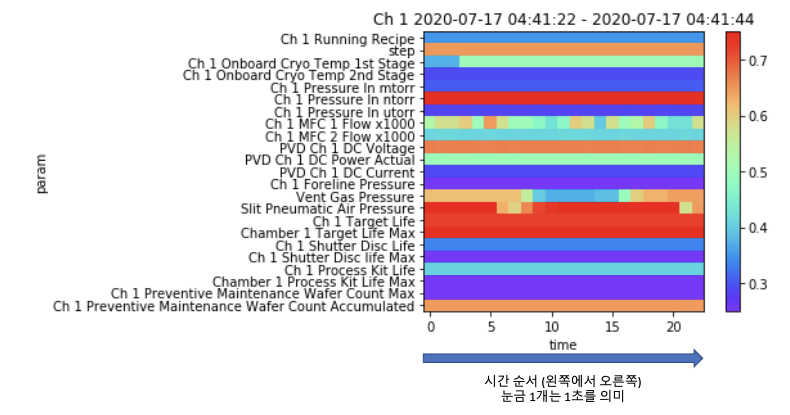
- 이미지의 x축은 시간 특성, y축은 파라미터 특성, 을 반영해야 한다. 따라서, 이미지 크기 (M,N)에서 M은 원시계열을 나누는 시간 단위 (window의 크기)이며, N은 파라미터의 개수여야 한다. 이미지 사이즈는 정사각형 (M=N)이어야 하므로, 결국 시계열을 자르는 시간 단위=파라미터의 개수여야 한다.
- 이후 CNN 계산을 위해, 되도록이면 이미지 크기를 짝수로 맞추는 것이 좋다 (특히, 2의 배수가 제일 적절, 32x32, 64 x 64)
- 해결방안 : 이미지 사이즈를 맞춰야 하는 경우에는 빈 부분을 디폴트값으로 채워도 좋을 것으로 예상됨(자동적으로 CNN에서 관련 없는 feature는 제외시킬 것 챔버로 나누지 않고 묶어서 이미지 인코딩해도 좋을 것 (동일한 시점에서 수집되는 데이터이기 때문에) 예를 들어, 1,2,3,4 챔버는 같은 공정으로 동일한 파라미터를 수집 (각각 23개) -> 23 * 4 = 92 -> 4개의 챔버 데이터의 92초동안의 데이터를 하나의 이미지로 인코딩 가능 혹은, 상관없이 사용되는 모든 챔버 1,2,3,4,C,D, Bu 등)의 데이터를 하나로 묶음 -> 100개 이상의 파라미터가 한번에 처리될 수 있을 것으로 예상
- RGB 방식의 문제 : 음수값 표현 음수값에 값을 더해 양수로 만들어주는 방법도 있지만, 그 경우 max로 표현 가능한 양수값의 범위가 좁아짐
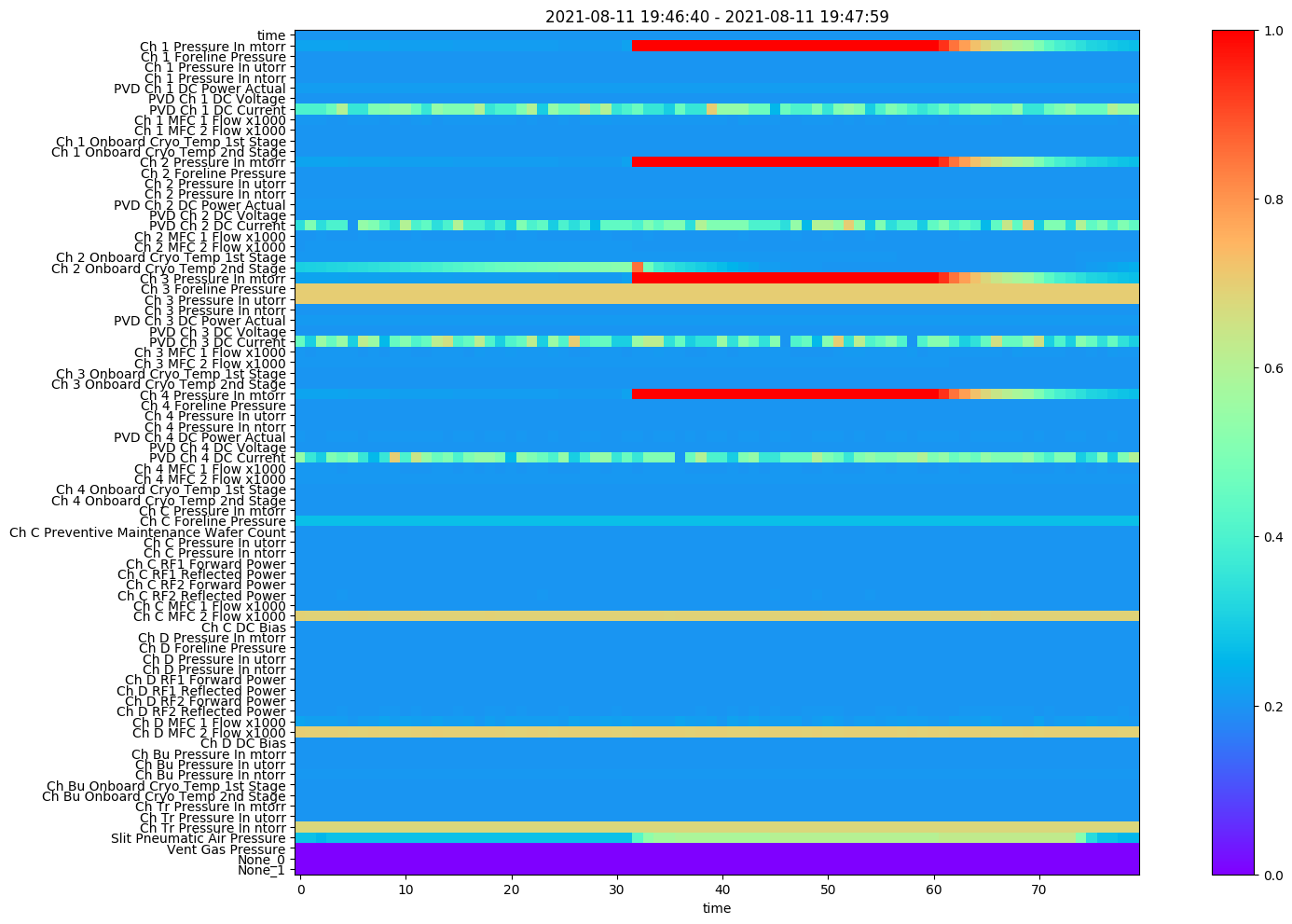

진행 방식
- 사용 모델: Efficient v1 B0 Transfer Learning
- 이미지 크기 : 80 x 80 (grayscale)이미지
- Chamber 1,2,3,4,C,D,Bu,Tr 파라미터 총 77개 + 데이터 크기 맞춰주기 위한 3의 공백 데이터
- 사용 데이터셋
- train 데이터 : 2021-08-09~2021-08-25 기간 데이터 (정상 이미지:17234, 비정상 이미지: 595, 비가동 155)
- valid 데이터 : 2021-08-01~2021-08-08 기간 데이터 (정상 이미지: 8255, 비정상 이미지:182, 비가동 208)
- test 데이터 : 2021-08-26~2021-08-31 (정상 이미지: 5768, 비정상 이미지: 152, 비가동 20)
- 비정상 데이터로 분류된 이미지의 confidence score를 위험도(anomaly score)로 사용 가능
- wafer 교체로 인한 비정상은 이후에 wafer count의 변화를 보고 위험도를 조정하도록
성능 저하 원인 분석
1) 정상 데이터와 비정상 데이터의 data imbalance
2) 알람 정보가 있어 비정상 데이터로 구분했지만, 해당 알람이 공정 이상과 관련 없는 경우
- 예를 들어, 단순히 wafer count가 바뀔 때에도 알람 정보가 있을 수 있지만, 장비의 고장과는 관련이 없어 실제로는 정상 데이터로 간주해야한다.
성능 저하 해결 방법
1) 제대로 분류되지 않은 이미지 확인 필요 -> 정상 이미지와 유사할 경우(이상치를 보이지 않는 경우), 해당 이미지 처리에 대한 고민 필요
2) data imbalance 해결방안
- 인공적으로 비정상 데이터를 생성
- 클래스에 상관없이 특정 기간동안의 데이터 csv 파일 전체를 이미지 array로 만들어 바로 학습시키는 방식이 아닌, 인코딩한 이미지를 클래스별로 저장한 뒤, 검수하고 데이터 개수를 맞춘 다음, load해서 학습시키는 방식으로 전환
- image load시 데이터 손실이 발생하는지 확인 필요
3) 다른 모델 적용(ResNet 등)
4) 다른 인코딩 방식 적용
- 데이터 특성에 따라 특징을 잘 추출할 수 있는 인코딩 방식이 따로 있을 수 있다
반응형

